Zasa suhlasim, ze obrovsky kus prace je o referencnych registroch aj ked si myslim ze pravda je uprostred. Podla mna je dolezitost jednotnej schemy a URI ako id namiesto nejakeho long datoveho typu na rovnakej urovni v zmysle ze to vie riesenie pohnut znova o uroven vyssie a zjednodusi integraciu systemov. Nakolko sme teraz v stave, ze sa na referencne registre len nabieha, tak pouzitim rovno URI sa riesenie nepredrazi a dostaneme za menej resp. rovnako penazi viac hodnoty.
1 Like
Možno trošku od veci, ale ozaj iba trošku.
My sme ani nikdy netvrdili, že spasenie slovenska a sémantický web je ekvivaletný vzťah. My sme presvedčený, že na istú množinu problémov (reprezentácia dát, integrácia, vyhľadávanie, riešenie referečných dát, riešenie duplicitných identifikátorov, a podobne), je lepší sémantický web než relačné databázy. Boli by sme radšej, keď tento názor zdieľalo čo najviac ľudí, ale dokážeme asi žiť aj bez toho, čo je ale škoda, no spolupracovať na Slovensku je často krát je bitch.
Tak či onak, za pár dní publikujeme nový LOD Slovakia, spolu s jednoduchým GUI (čo robia naši FIIT študenti), kde si myslím bude krásne viditeľná sila prepojených dát (mashup).Opäť len pripomínam, že ak niekto by mal mať zálusk na LinkedData okrem štátu a biznisu, tak je to transparency, …, ale to sa už zase točím dookola.
Je to je len nadstavba, to nie su nejake alternativy ci iny pristup. Z relacnej databazy ci dokonca CSV, kde su vsetky data so spravnymi idckami urobim RDF triplety na pockanie. Ved kopec triplestorov ma bud datove pumpy z relacnych db alebo ich kedysi pouzivali dokonca priamo ako engine pod sebou. Ano je pravda, ze nativne riesenie duplicit cez sameAs je fajn feature, lenze nic co by sa nedalo namodelovat hocikde inde. Nie je to nic ine ako dalsia mapovacia tabulka s dvoma idckami/uri.
Silu prepojenych dat nikto nezpochybnuje. Dokonca aj federovane queries maju nieco do seba. Teda ked si odmyslim, ze to je stale vyskumny problem.
Povedzme si ciel.
Je cielom taketo SPARQL dopyty mat niekde v read replikach na dopytovanie nad open data alebo chceme aby sa postupne preslo na SPARQL ako linqua franca ktorou sa bude riesit zdielanie/dopytovanie dat ISVS medzi sebou?
To prve je ok a nevidim problem, pri tom druhom by som bol velmi opatrny.
2 Likes
Za mna osobne… pre mna je dolezite za data budu mat standardizovane schemy a URI identifikatory. Technologie treba pouzivat na veci na ktore su urcene tj. SPARQL a tieto veci budu prirodezne out of box ale ked systemu X vyhovuje pre interne procesy vyuzitie nieco ineho tak nech si to pouzije, dolezite je ze na rozhraniach MUSI komunikovat znova cez standardizovane URI a schemy cim si to samozrejme skomplikuje ale rozne aplikacie maju rozne poziadavky.Viem si predstavit SPARQL ako jazyk pre Open Data. Pre mna bude uspech ak sa to podari na datovej urovni cele zohrat a to je teraz aj priorita.
2 Likes
Obnovuje sa cinnost PS1, takze vid Komisia pre štandardy ISVS - PS1 .
1 Like
Ahojte,
dovolím si updatnúť toto vlákno, za posledné tri roky sme v Dátovej kancelárii verím že hodne posunuli túto tému. Centrálny model je prenesený na github:
pričom najnovšie veci sú zatiaľ updatnúté do develop verzie (následne pôjdu na štandardizáciu, až potom sa mergnú do hlavnej verzie).
CMÚ implementovalo viacero projektov, resp. implementácia práve prebieha. Krátky prehľad môžete vidieť v časti govdata-examples.
Navyše, od marca je v platnosti Smernica o interoperabilnej EÚ:
https://eur-lex.europa.eu/legal-content/en/TXT/?uri=CELEX:32024R0903
Ako to všetko spolu súvisí sa môžete dozvedieť na dnešnom školení o 13:00:

Link na pripojenie
kde budem z tohto pohľadu hovoriť aj o rozdieloch symbolickej a štatistikej AI, takže ste všetci vítaní. Záznam tu neskôr zavesím.
Ahojte, pripájam video k 1.časti školenia - Dátová interoperabilita I.:

Ahojte, po cca 3 a polročnej ceste sa môj čas na MIRRI zajtra končí.
Dnes o 13:00 ešte robím posledné, rozlúčkové školenie:
Dátová interoperabilita II.
Tu je agenda:

A tu link na pripojenie:
1 Like
----------------------------------------------------------------------
Ahojte, aj keď už nerobím na MIRRI, rád by som pokračoval v rozvoji Centrálneho modelu údajov. Kým som tam robil, tak sme CMÚ začali publikovať na GitHube (slovak-egov), takže je možné ho jednoducho forknúť, samostatne rozvíjať a neskôr snád raz opätovne zlúčiť. ![]()
No a v poslednom čase som mal možnosť pracovať na niektorých štandardoch ako ELM (vzdelávanie), ESCO (zamestnanosť) a ERA (železnice), pričom to sú oblasti, ktoré v CMÚ zatiaľ nie sú pokryté. Z týchto troch sa chcem špeciálne zamerať na železnice – pomôcť posunúť naše železničné opendata (era-ready) a snáď v zápätí poznanie, čo slovenským železniciam skutočne chýba (kamera vs. bezpečnostné systémy) . No sa samozrejme chcel by som sa zamerať aj na používanie ELI (legislatíva), EPO (verejné obstarávanie) a ďaľšie modely.
Aby sa dalo v tejto veci pohnúť, forkol som CMU zo slovak-egov na semantickyweb:
kde je main + develop + feature vetvy pre elm, esco, era, dcat-ap-sk a ďaľšie tématické rozvojové vetvy CMÚ.
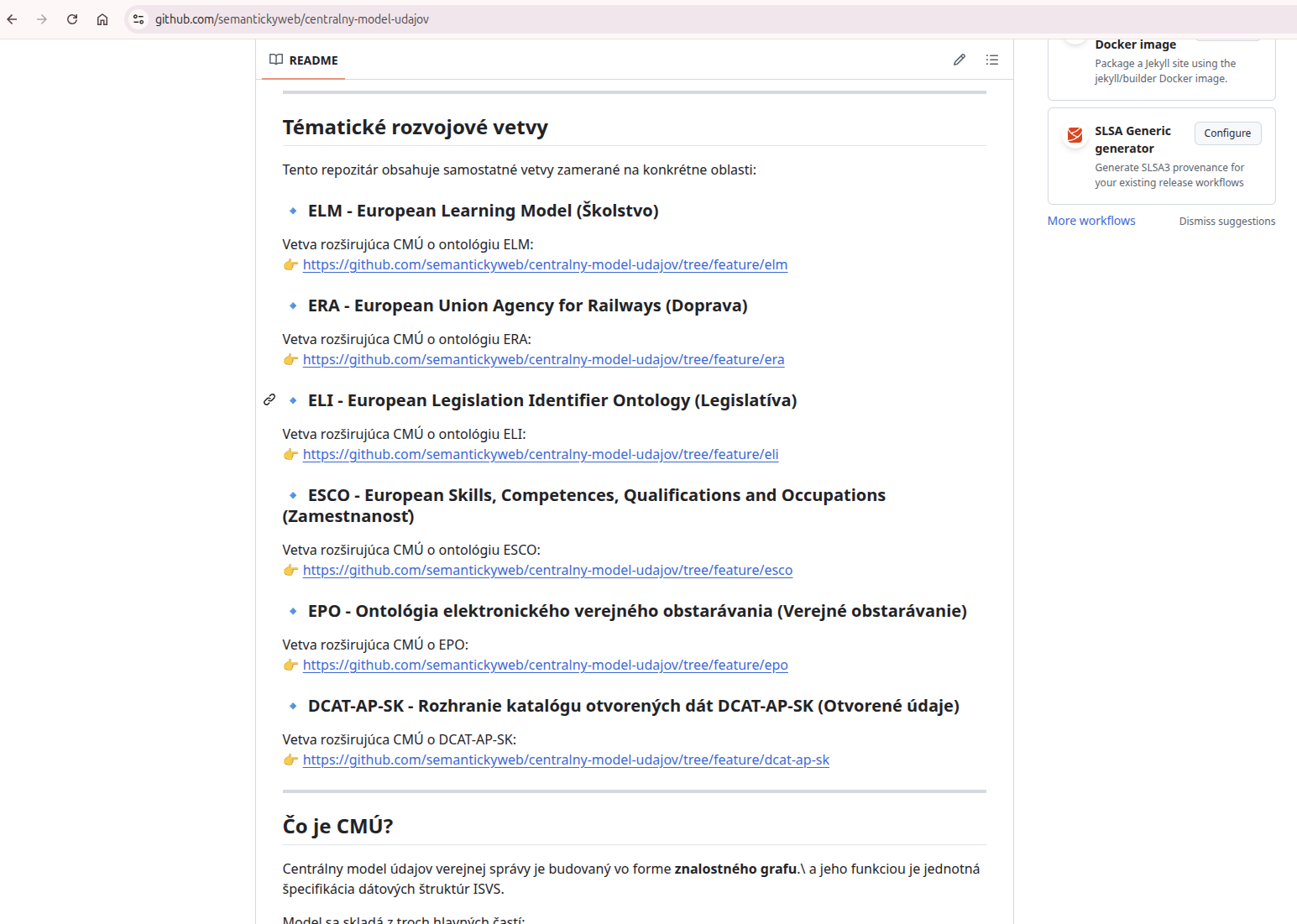
Najbližší plán je na konci roka 2026 zhrnúť všetky naše rozšírenia do jedného celku, ktorý bude reprezentovať návrh na novú verziu CMÚ. Tento návrh by sme radi potom alebo neskôr prezentovali na PS1.
Ak chcete vidiet rovno samotné zmeny ktoré pôjdu do rozšírenia 2026, stačí sa pozrieť na otvorené pull-requesty:
https://github.com/semantickyweb/centralny-model-udajov/pulls

Ak by sa chcel niekto zapojiť, je absolútne vítaný.
2 Likes